2023.07.26 코드스테이츠 75회차. ( 고가용성 )
프록시 서버
프록시 서버는 클라이언트가 서버와 소통 할 때, 서버에 바로 접근하지 않고 자신을 통해 서버에 접근 할 수 있도록 해주는 대리서버 이다
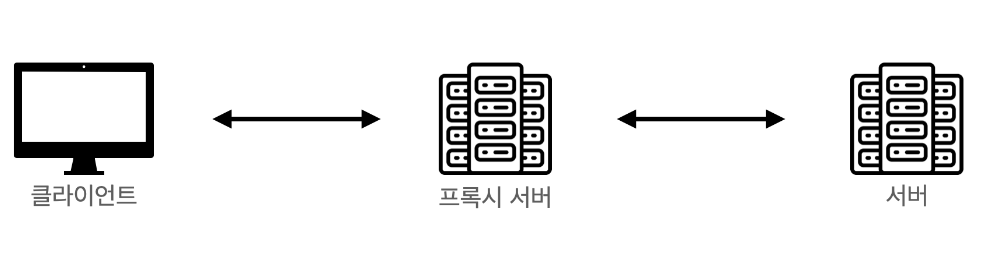
보통 일반 사용자는 지역이 제한되어있는 서비스를 이용하기 위해 우회하거나, 캐시를 통해 더 빠른 이용을 하기 위해 프록시 서버를 사용한다
프록시 서버의 종류
프록시 서버는 위치에 따라 Forward Proxy와 Reverse Proxy 두 가지로 나뉜다
록시 서버가 클라이언트에 가까이 있는지, 서버에 가까이 있는지로 구분할 수 있다
1. Forward Proxy

Forward Proxy는 클라이언트 가까이에 위치한 프록시 서버로 클라이언트를 대신해 서버에 요청을 전달한다
주로 캐싱을 제공하는 경우가 많아 사용자가 빠른 서비스 이용을 할 수 있도록 도와준다
- 캐싱을 통해 빠른 서비스 이용 가능 클라이언트는 서비스의 서버가 아닌 프록시 서버와 소통하게 됩니다. 그러한 과정에서 여러 클라이언트가 동일한 요청을 보내는 경우 첫 응답을 하며 결과 데이터를 캐시에 저장해놓고, 이후 서버에 재 요청을 보내지 않아도 다른 클라이언트에게 빠르게 전달할 수 있습니다.
- 보안 클라이언트에서 프록시 서버를 거친 후 서버에 요청이 도착하기 때문에, 서버에서 클라이언트의 IP 추적이 필요한 경우 클라이언트의 IP가 아닌 프록시 서버의 IP가 전달됩니다. 서버가 응답받은 IP는 프록시 서버의 IP이기 때문에 서버에게 클라이언트를 숨길 수 있습니다.
2. Reverse Proxy
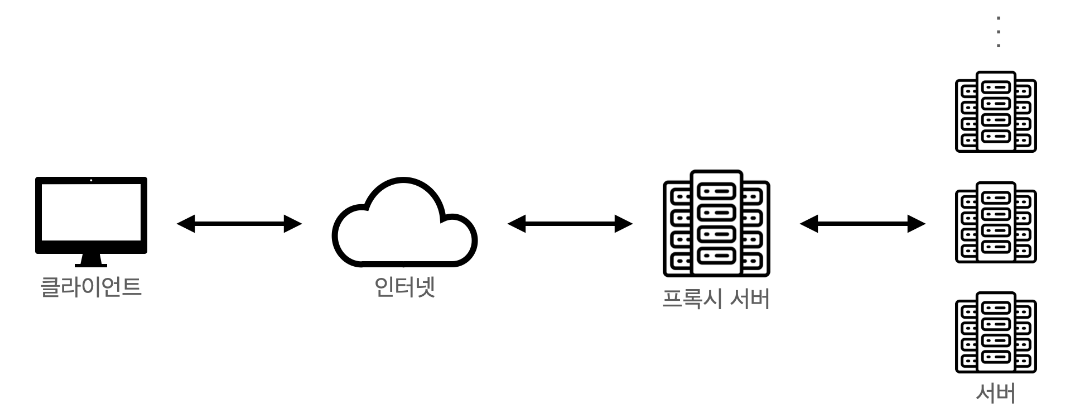
Reverse Proxy는 서버 가까이에 위치한 프록시 서버로 서버를 대신해서 클라이언트에 응답을 제공한다
분산처리를 목적으로 하거나 보안을 위해 프록시 서버를 이용한다
- 분산처리 클라이언트 - 서버 구조에서 사용자가 많아져 서버에 과부하가 올 경우를 위해 부하를 분산할 수 있습니다. Reverse Proxy 구조에서 프록시 서버로 요청이 들어오면 여러대의 서버로 요청을 나누어 전달 후 처리합니다.
- 보안 Forward Proxy와 반대로 Reverse Proxy는 클라이언트에게 서버를 숨길 수 있습니다. 클라이언트 입장에서의 요청보내는 서버가 프록시 서버가 되므로 실제 서버의 IP주소가 노출되지 않습니다.
로드 밸런서
서비스에 너무 많은 사용자(클라이언트)가 접속을 하면 서버에는 과부하가 오게 될 것이다.
과부하로 인해 서버가 원활한 서비스를 제공하지 못하는 경우를 해결하기 위해 크게 서버의 하드웨어를 업그레이드하는 방법과 서버의 갯수를 늘리는 방법, 두가지 선택을 할 수 있다
1. Scale - up
Scale-Up은 물리적으로 서버의 사양을 높이는 하드웨어적인 방법이다
서버의 수를 늘리지 않고 프로그램 구현에 있어 변화가 필요없다는 장점이 있지만 서버의 사양을 높이는데엔 굉장히 높은 비용이 들고, 하드웨어의 업그레이드엔 한계있다는 큰 단점이 있다
또한 사양을 늘린만큼 클라이언트의 요청이 더욱 많아진다면, 서버에 발생하는 부하는 여전히 해결하지 못한 상황이 된다
2. Scale - out
Scale-Out은 서버의 갯수를 늘려 하나의 서버에 줄 부하를 분산시키는 방법이다
많은 요청이 오더라도 여러대의 서버가 나눠서 처리를 하기 때문에 서버의 사양을 높이지 않고도 비교적 저렴한 방법으로 부하를 처리할 수 있다
Scale-Out방법으로 여러대의 서버로 부하를 처리하는 경우, 클라이언트로부터 온 요청을 여러 서버 중 어느 서버에 보내서 처리해야 하는 지는 로드 밸런서가 교통정리를 해주는 역할을 하게 된다
여러 서버에 교통정비를 해주는 기술 혹은 프로그램을 로드밸런싱 이라고 부른다
로드 밸런서의 종류
로드 밸런서는 클라이언트의 요청을 어떤 것을 기준으로 분산시키냐에 따라 네 가지의 종류로 나뉩니다.
로드 밸런서의 종류 로드밸런싱의 기준
| L2 | 데이터 전송 계층에서 Mac 주소를 바탕으로 로드 밸런싱 합니다. |
| L3 | 네트워크 계층에서 IP 주소를 바탕으로 로드 밸런싱 합니다. |
| L4 | 전송 계층에서 IP주소와 Port를 바탕으로 로드 밸런싱 합니다. |
| L7 | 응용 계층에서 클라이언트의 요청을 바탕으로 로드 밸런싱 합니다. (예, 엔드포인트) |
오토 스케일링

오토 스케일링은 클라우드 컴퓨팅에서 자동으로 서버 리소스를 확장 또는 축소하여 서버 인프라의 유지 관리를 최소화하는 기능이다
일반적으로, 서버 부하가 증가하면 오토 스케일링은 자동으로 추가 리소스를 할당하여 서버가 부하를 처리할 수 있도록한다
서버 부하가 감소하면 오토 스케일링은 자동으로 리소스를 줄여 불필요한 리소스 사용을 방지한다
오토 스케일링은 클라우드 컴퓨팅의 핵심 기능 중 하나이며, 서버 부하를 신속하게 처리하고 서버의 성능을 유지하는 데 매우 유용하다
자동으로 스케일 아웃과 스케일 인을 할 수 있는 방식
스케일 아웃
서버가 부하를 감당할 수 없을 정도로 많은 사용자들이 서비스를 이용하고 있을 때, 서버가 더 많은 리소스를 사용할 수 있도록 하는 것을 '스케일 아웃'이라고 한다
이를 통해 사용자들이 서비스를 계속 사용할 수 있도록 서버의 성능을 유지할 수 있다
스케일 아웃은 수동으로 진행할 수도 있지만, 오토 스케일링을 사용하면 자동으로 리소스를 확장 또는 축소할 수 있어 효율적으로 서버 인프라를 관리할 수 있다
스케일 인
스케일 인은 서버 부하가 감소할 때 사용되며, 리소스 사용량을 줄여 불필요한 리소스 사용을 방지한다
이를 통해 서버 인프라의 비용을 절감할 수 있다
예를 들어, 서버 부하가 적을 때는 더 이상 필요하지 않은 서버를 종료하여 비용을 절감할 수 있다
스케일 인은 수동으로 진행할 수도 있지만, 오토 스케일링을 사용하면 자동으로 리소스를 확장 또는 축소할 수 있어 효율적으로 서버 인프라를 관리할 수 있다
오토 스케일링 구성 요소
스케일링 그룹
오토 스케일링 그룹은 서버 인스턴스의 집합입니다. 이 그룹 안의 인스턴스들은 동일한 크기의 이미지를 사용하며, 동일한 네트워크 구성과 보안 그룹 구성을 가지고 있습니다. 또한, 오토 스케일링 그룹 안의 인스턴스들은 동일한 자동 스케일링 정책을 공유합니다.
자동 스케일링 정책
자동 스케일링 정책은 리소스를 자동으로 확장하거나 축소하는 데 사용되는 규칙입니다. 이 규칙은 다음과 같은 요소로 구성됩니다.
- 조건: 자동 스케일링이 발생하는 조건입니다. 예를 들어, CPU 사용률이 80% 이상인 경우 자동 스케일링이 발생합니다.
- 동작: 자동 스케일링이 발생했을 때 취해지는 동작입니다. 예를 들어, 인스턴스를 2개 추가하는 것입니다.
로드 밸런서
로드 밸런서는 서버 인스턴스 간의 트래픽을 분산시키는 데 사용됩니다. 로드 밸런서는 클라이언트의 요청을 여러 서버 인스턴스로 분배하여 부하를 분산시킵니다. 이를 통해 애플리케이션의 가용성을 높일 수 있습니다.
Cloud Watch
CloudWatch는 AWS에서 제공하는 모니터링 서비스입니다. CloudWatch를 사용하여 리소스 사용률을 모니터링하고, 자동 스케일링 정책의 조건으로 사용할 수 있습니다.
오토스케일링 동작 원리와 이점
다음과 같은 시나리오를 가정해봅니다.
- EC2 인스턴스 클러스터가 있고 10개의 인스턴스가 필요한 상황입니다.
- 구성에 문제가 발생했습니다. (인스턴스와 같은 서버나 동작하는 소프트웨어의 문제)
- Cloud Watch에서 문제를 감지하고 오토스케일링됩니다.
- 오토 스케일링 조건 설정값(시작 구성이라고 얘기합니다)에 맞는 인스턴스를 생성하고 오토 스케일링 클러스터에 넣습니다.
이처럼 자동으로 리소스가 관리되도록 하는것이 수동으로 리소스를 관리할때 보다 뚜렷한 이점이 있습니다. 오토 스케일링은 다음과 같은 이점을 제공합니다.
- 자동화된 리소스 관리: 서버 부하가 증가하면 자동으로 리소스를 제공하여 애플리케이션 성능을 유지하고, 서버 부하가 감소하면 자동으로 리소스를 해제하여 비용을 절감합니다.
- 높은 가용성: 서버 부하가 증가하더라도 자동으로 리소스를 확장하기 때문에, 서버가 다운되는 것을 방지하고 애플리케이션이 항상 사용 가능하도록 합니다.
- 비용 절감: 필요한 리소스만 사용하여 비용을 절감할 수 있습니다.
- 유연성: 서버 인프라를 즉시 확장하거나 축소하여 더욱 빠르게 대응할 수 있습니다.