2023.05.12 코드스테이츠 23일차. ( 자료구조 / stack, queue )
자료구조
- data 는 문자, 숫자, 소리, 그림, 영상 등 실생활을 구성하고 있는 모든 값
- 데이터는 분석하고 정리하여 활용해야만 의미를 가질 수 있다
- 데이터를 체계적으로 정리하여 저장해 두는 것이 데이터를 활용하는데 있어 훨씬 유리하다
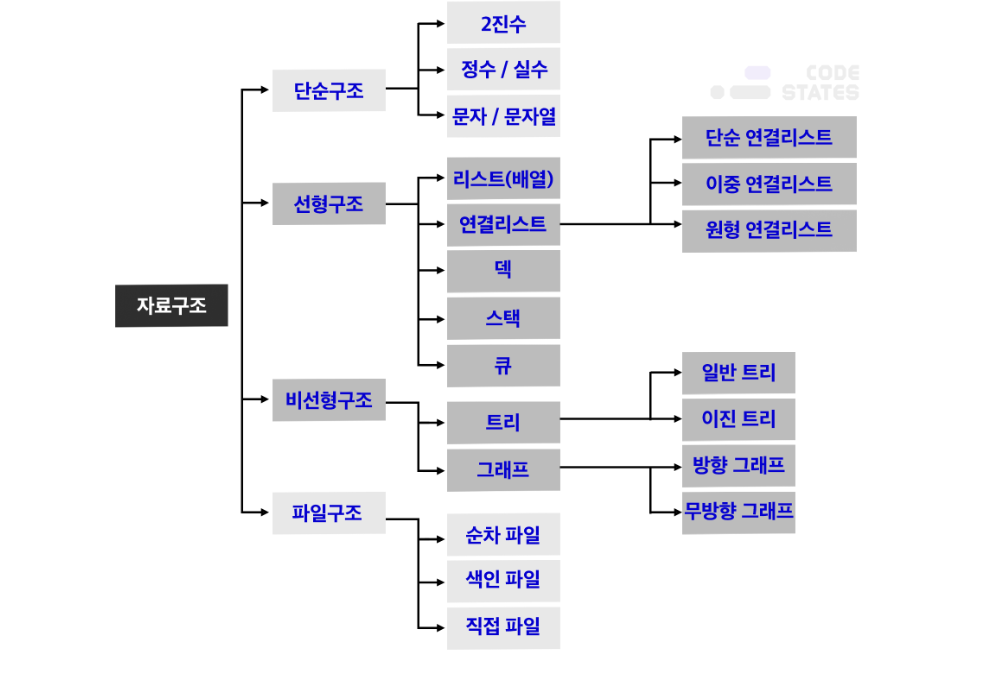
- 자주 등장하는 네가지의 자료 구조 : Stack, Queue, Tree, Graph
Stack
- data를 순서대로 쌓는 자료구조
- 먼저 들어간 데이터가 제일 나중에 나오는 ( 제일 마지막에 들어간 데이터가 제일 먼저 나오는 )
- 입력과 출력이 하나의 방향으로 이루어지는 제한적 접근에 있다
- LIFO ( Last In First Out ) / FILO( First In Last Out )
- Stack에 데이터를 넣는 것을 Push, 데이터를 꺼내는 것을 POP 라고 한다
Stack 의 특징
1. LIFO : 먼저 들어간 데이터는 제일 나중에 나오는 후입 선출의 구조이다
2. 데이터는 하니씩 넣고 뺄 수 있다 : 데이터가 아무리 많이 있어도 하나씩 데이터를 넣고 뺀다 / 한꺼번에 여러개를 넣거나 뺼 수 없다
3. 하나의 입출력 방향을 가지고 있다 : 데이터의 입출력 방향이 같다. ( 입출력 방향이 여러개 라면 Stack자료 구조라고 볼 수 없다 )
- push(E item): 스택의 맨 위에 주어진 요소를 추가합니다.
- pop(): 스택의 맨 위에 있는 요소를 삭제하고 반환합니다.
- peek(): 스택의 맨 위에 있는 요소를 반환합니다. 삭제하지 않습니다.
- empty(): 스택이 비어 있는지 여부를 반환합니다.
- search(Object o): 주어진 요소가 스택에서 어느 위치에 있는지를 찾아 해당 위치의 상대적 거리(스택의 맨 위에서부터)를 반환합니다. 만약 스택에 해당 요소가 없다면 -1을 반환합니다.
Stack 자료 구조의 장점
1. 스택은 후입 선출 ( LIFO ) 구조를 가지기 때문에 스택에 저장된 데이터를 가져오는 속도가 매우 빠르다.
- 삽입과 삭제가 항상 스택의 맨 위에서 이루어 진다.
- 스택에서 데이터를 삽입하거나 삭제 할 때 다른 데이터의 위치를 변경할 필요가 없다
2. 자바에서 스택을 기본 자료 구조로 제공하기 때문에 별도의 라이브러리나 모듈을 설치 할 필요가 없다
- 자바에서는 따로 스택을 구현하지 않아도 이미 Stack 클래스가 구현되어 있다
Stack 자료 구조의 단점
1. 크기 제한이 없다
- 데이터를 저장할 때 크기가 제한되지 않기 때문에 메모리 사용량이 불필요하게 증가할 수 있다
- 이러한 문제를 해결하기 위해서는 스택의 크기를 미리 정해놓거나, 동적으로 크기를 조정하는 방법을 사용해야 한다
2. Stack 클래스는 Vector 클래스를 상속 받아 구현되어 있어, 크지를 동적으로 조정하지 않는다 ( JAVA에서 제공하는 Stack 클래스 한정 )
- 이 배열의 크기는 처음에 지정된 크기만큼만 할당되고, 스택에 저장되는 데이터의 개수가 배열의 크기를 초과하면 새로운 배열을 할당하고, 기존 데이터를 새로운 배열로 복사하는 작업을 수행한다
- 크기가 자주 변하는 스택에서는 다른 자료 구조를 사용하는 것이 더 효율적일 수 있다
3. Stack 클래스는 Vector 클래스를 상속받아 구현되어 있어, 중간에서 데이터를 삽입, 삭제 할 수 있게 됩니다. ( JAVA에서 제공하는 Stack 클래스 한정이다 )
- Stack 클래스는 Vector 클래스를 상속받아 구현되어 있기 때문에, Vector 클래스의 모든 메서드를 상속받아 사용할 수 있다
- Stack 클래스에서는 Vector 클래스에서 상속받은 메서드 중에서 일부 메서드를 오버라이딩하여 구현하고 있다
Queue
- 가장먼저 들어온 데이터가 가장 먼저 나가는 구조를 가진다
- 가장먼저 들어온 데이터가 나가기 전까지 그 뒤에 들어온 데이터는 나갈 수 없다
Queue 의 특징
1. FIFO ( First in First Out ) : 먼저 들어간 데이터가 제일 처음에 나오는 선입선출의 구조를 가지고 있다
2. 데이터는 하나씩 넣고 뺼수 있다 : 데이터가 아무리 많이 있어도 하나씩만 데이터를 꺼내고 뺼수 있다
3. 두개의 입출력 방향을 가지고 있다 : 데이터의 입력 출력 방향이 다르다
- add(E item): 큐의 뒤쪽에 주어진 요소를 추가합니다.
- offer(E item): 큐의 뒤쪽에 주어진 요소를 추가합니다. 큐가 가득 찼을 때 false를 반환합니다.
- remove(): 큐의 맨 앞쪽에 있는 요소를 삭제하고 반환합니다.
- poll(): 큐의 맨 앞쪽에 있는 요소를 반환하고 삭제합니다. 큐가 비어있으면 null을 반환합니다.
- peek(): 큐의 맨 앞쪽에 있는 요소를 반환합니다. 삭제하지 않습니다.
- element(): 큐의 맨 앞쪽에 있는 요소를 반환합니다. 큐가 비어있으면 NoSuchElementException이 발생합니다.
- isEmpty(): 큐가 비어 있는지 여부를 반환합니다.
Queue 자료 구조의 장점
1. 자료를 먼저 넣은 순서대로 데이터를 꺼내서 처리 할 수 있다, 이러한 자료 구조의 특징으로 처리해야할 작업이 어려개 있을 경우, 효율 적인 데이터 처리가 가능하다
- 선입선출 원칙을 따르기 떄문에 가장 먼저 삽입된 데이터가 가장 먼저 삭제되고 가장 나중에 들어온 데이터가 가장 나중에 삭제 된다.
- 처리해야 할 데이터나 작업을 차례대로 처리할 수 있다
- 앞(front)에서는 가장 오래전에 삽입된 데이터가 위치하고, 가장 뒤(rear)에서는 가장 최근에 삽입된 데이터가 위치한다
- 데이터를 삽입하는 순서와 삭제하는 순서가 동일하게 유지 되어야 한다
2. Queue는 쉽입과 삭제가 각각 양 끝에서 이루어 지며 원소를 삭제하는 연산이 없으므로, 다른 자료 구조에 비해 상대적으로 빠른 속도를 보인다
- Queue는 삽입과 삭제가 각각 Queue 끝단에서 이루어 지기 때문에 중간에 잇는 원소를 삭제하는 연산이 없다
- 배열의 경우, 중간에 있는 원소를 삭제하려면 삭제한 원소 이후의 모든 원소를 한 칸씩 앞으로 이동시켜야 한다.
- 중간의 원소를 삭제한다면, 이후의 배열을 복사하고 다시 순회하며 데이터를 삽입하는 과정을 거쳐야 한다
- 삭제한 원소 뒤에 새로운 원소를 삽입하려면 빈자리를 만들기 위해 이후의 원소들을 한 칸씩 뒤로 밀어야 하므로 삽입 연산에서도 전체 배열을 순회해야 한다
- Queue에서는 삽입 연산은 Queue의 끝단에서 새로운 원소를 추가하는 것으로 끝나며, 삭제 연산은 Queue의 첫 번째 원소를 삭제하는 것으로 끝난다 따라서, Queue에서의 삽입과 삭제 연산은 단 한 번의 실행만으로 처리할 수 있다
3. JAVA에서는 Queue를 기본 자료 구조로 제공하기 때문에 별도의 라이브러리나 모듈을 설치할 필요가 없다
Queue 자료 구조의 단점
1. Queue는 자료 구조의 가장 앞에서 데이터를 꺼내는 연산과 가장 뒤에서 데이터를 추가하는 연산만 가능하기 때문에 중간에 는 데이터를 조회하거나 수정하는 연산에는 적합하지 않다.
- 데이터를 가장 먼저 추가한 위치에서부터 차례로 데이터를 처리하며, 가장 나중에 추가된 위치에서 새로운 데이터를 추가한다
- 이러한 구조 때문에 Queue는 특정 위치의 데이터를 조회하거나 수정하는 연산에 적합하지 않다
- Queue에서는 가장 앞에서 dequeue 연산(add)으로 데이터를 삭제하거나, 가장 뒤에서 enqueue 연산(poll)으로 데이터를 추가하는 것만 가능하다 Queue는 다른 위치의 데이터에 직접 접근하여 데이터를 변경하는 연산이 불가능하며, 중간에 있는 데이터를 조회하는 것도 불가능ㅎ다. 따라서 Queue는 데이터를 순차적으로 처리하는 데 적합한 자료 구조 이다
2. 크기 제한이 없어서 메모리의 낭비가 발생할 수 있다 ( JAVA에서 제공하는 Queue 인터페이스 경우 )
- Queue 인터페이스는 크기 제한이 없는 큐를 구현할 수 있도록 설계되어 있다
- 메모리 낭비의 가능성을 높입니다. 크기 제한이 있는 큐를 구현할 때는, 이를 직접 구현하거나 기존의 Queue 인터페이스를 상속받아 크기 제한을 추가한 클래스를 구현해야 한다
3. iterator() 메서드가 지원되지 않는다
- Queue 인터페이스는 iterator() 메서드를 지원하지 않는다. 이는 Queue 인터페이스가 FIFO(First-In-First-Out) 구조를 갖기 때문이다
- 큐의 데이터를 순회할 때는, peek() 메서드와 poll() 메서드를 사용하여 각각의 데이터를 차례대로 가져와야 한다
4. remove( Object o ) 메서드의 동작이 불명확 하다
- Queue 인터페이스에서 제공하는 remove(Object o) 메서드는 해당 객체를 큐에서 삭제한다
- 이 메서드는 큐가 중복된 객체를 허용하는 경우, 어떤 객체가 삭제되는지 명확하지 않다
- poll() 메서드를 사용하여 원하는 객체를 삭제할 수 있다.
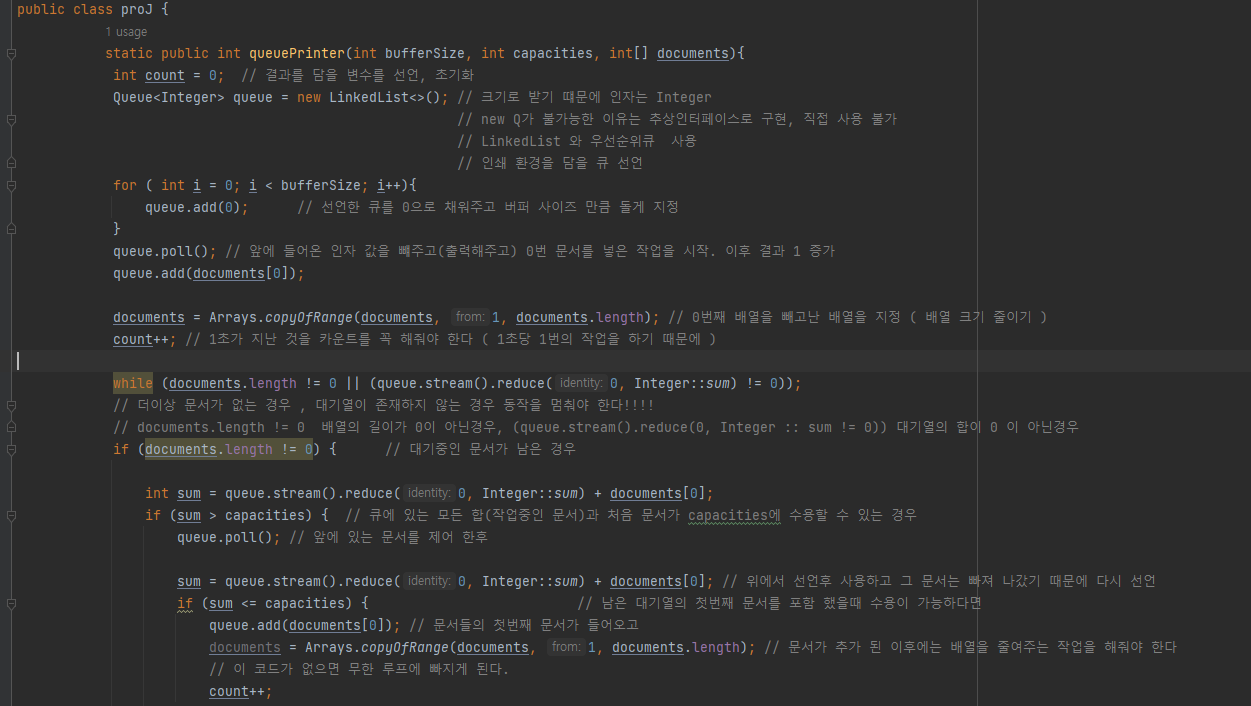
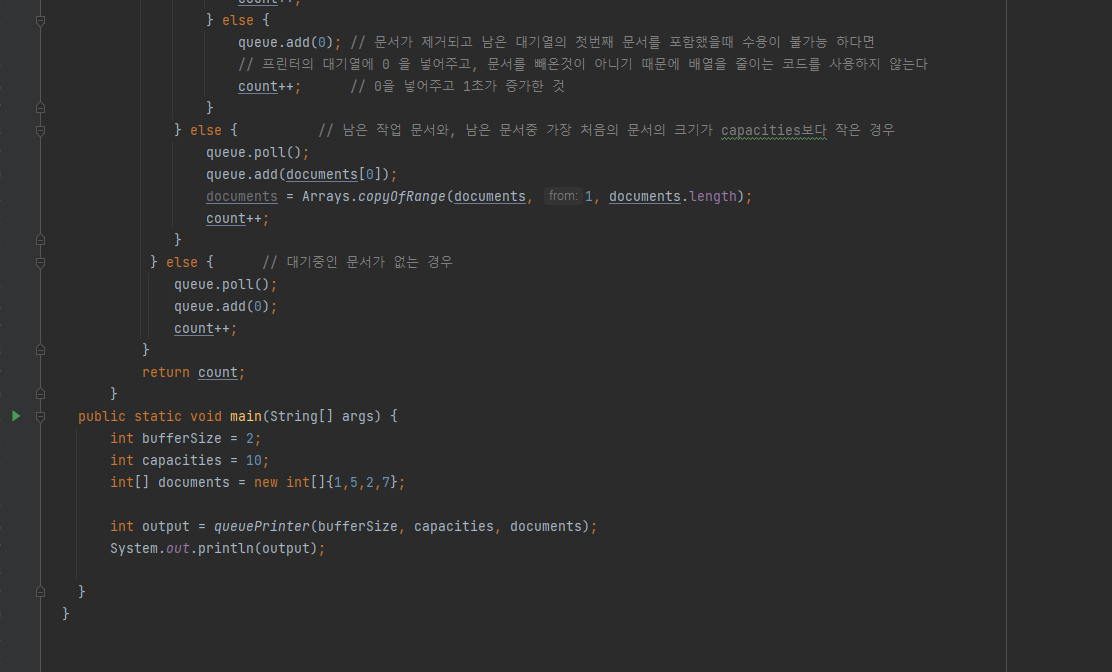
- Queue를 이용한 코드 구현
## 금일은 자료구조의 종류인 스택과 큐를 학습하였다. 둘다 기본적인 배열 형태의 구조인건 동일하나
선입선출이냐 후입선출이냐의 구조를 큰 차이를 보인다.
또한 스택은 한방향으로만 입출력이 되는 반면 큐는 빨대와 비슷한 구조 양쪽으로 입출력이 되는 구조이다.
오늘 자료구조에 대해 처음 다뤄 보는 것이라 다른 배열의 명령어와 메서드의 기능을 이용하여 문제 풀이는 가능하지만 스택이나 큐를 이용해서는 문제해결을 하는데에 있어서 어려움을 겪었다.